
Page 213 - The-5th-MCAIT2021-eProceeding
P. 213
(1)
∑ ∈
( , ) =
| |
( , ) = ∈ ( ) (2)
We employ the model-based CF method, namely the SVD algorithm, to generate the recommendations for
the groups. Recommendation through GRSs represented as in (3) with reference to the target group, is a set
) and are utility functions for items based on group members .
of available items ( ,
(3)
( , ) = ( , )
∈
3. Result and Discussion
As for experimental evaluation, we used the Movielens 1 Million (ML1M) dataset, which comprises 6040
users and 3952 movies with a total of 1,000,209 ratings. DBpedia's two attributes had been chosen:
'dbo:director' and 'dbo:starring'. We employed 5-fold cross-validation over 15 formed groups and evaluated
the GRS-LOD model's effectiveness using a consistent ten-size group (ten users per cluster).
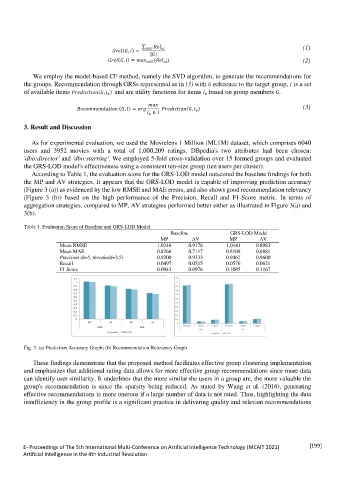
According to Table 1, the evaluation score for the GRS-LOD model outscored the baseline findings for both
the MP and AV strategies. It appears that the GRS-LOD model is capable of improving prediction accuracy
(Figure 3 (a)) as evidenced by the low RMSE and MAE errors, and also shows good recommendation relevancy
(Figure 3 (b)) based on the high performance of the Precision, Recall and F1-Score metric. In terms of
aggregation strategies, compared to MP, AV strategies performed better either as illustrated in Figure 3(a) and
3(b).
Table 1. Evaluation Score of Baseline and GRS-LOD Model
Baseline GRS-LOD Model
MP AV MP AV
Mean RMSE 1.0246 0.9178 1.0141 0.8983
Mean MAE 0.8266 0.7117 0.8108 0.6881
Precision (k=5, threshold=3.5) 0.9200 0.9333 0.9467 0.9600
Recall 0.0497 0.0515 0.0576 0.0621
F1 Score 0.0943 0.0976 0.1085 0.1167
Fig. 3. (a) Prediction Accuracy Graph; (b) Recommendation Relevancy Graph
These findings demonstrate that the proposed method facilitates effective group clustering implementation
and emphasizes that additional rating data allows for more effective group recommendations since more data
can identify user similarity. It underlines that the more similar the users in a group are, the more valuable the
group's recommendation is since the sparsity being reduced. As stated by Wang et al. (2016), generating
effective recommendations is more onerous if a large number of data is not rated. Thus, highlighting the data
insufficiency in the group profile is a significant practice in delivering quality and relevant recommendations
E- Proceedings of The 5th International Multi-Conference on Artificial Intelligence Technology (MCAIT 2021) [199]
Artificial Intelligence in the 4th Industrial Revolution