
Page 87 - The-5th-MCAIT2021-eProceeding
P. 87
2.2. Feature selection
Features with weightage of information gain above zero were selected. Then the matrix correlation was
performed to select only correlation weight that exceeds 0.5. As for the imbalanced data handling, SMOTE
techniques (Chawla et. al. 2002) were used. Details on selected features are shown in Table 1.
2.3. Prediction modelling
Dataset treated with SMOTE dataset has achieved better result for all matrix evaluations for both classes
compared to the original dataset although there was a slightly decrease in accuracy, specificity, FPR readings,
classification error and MSE. Models with SMOTE capabilities predict both survival and death classes with
overall accuracy was 98.85%. Thus, this dataset will be used to further improved the classification algorithm.
Two main phase that encompasses training phase and testing phase (Hsieh et al. 2019). Training phase
requires 70% while the rest 30% for the testing portion. 10-fold crossvalidation were also arried out as an error
estimator for 70% training data thus reducing error variation, estimating accurate performance and to avoid
overfitting.
The experiment was conducted on three algorithmic models called Gradient Boosted Decision Tree (GBDT),
K-Neighbor Nearest (KNN) and Artificial Neural Network (ANN). Parameter optimization carried out as well
to find optimal performance which reduces the loss function for better performance.
3. Result
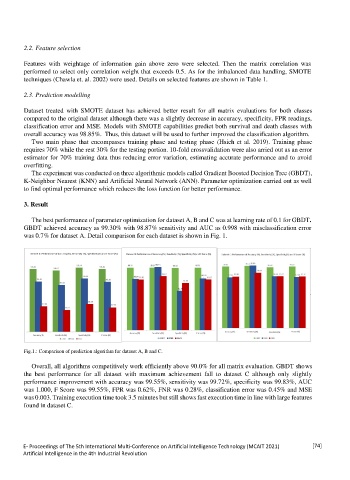
The best performance of parameter optimization for dataset A, B and C was at learning rate of 0.1 for GBDT.
GBDT achieved accuracy as 99.30% with 98.87% sensitivity and AUC as 0.998 with misclassification error
was 0.7% for dataset A. Detail comparison for each dataset is shown in Fig. 1.
Fig.1.: Comparison of prediction algorithm for dataset A, B and C.
Overall, all algorithms competitively work efficiently above 90.0% for all matrix evaluation. GBDT shows
the best performance for all dataset with maximum achievement fall to dataset C although only slightly
performance improvement with accuracy was 99.55%, sensitivity was 99.72%, specificity was 99.83%, AUC
was 1.000, F Score was 99.55%, FPR was 0.62%, FNR was 0.28%, classification error was 0.45% and MSE
was 0.003. Training execution time took 3.5 minutes but still shows fast execution time in line with large features
found in dataset C.
E- Proceedings of The 5th International Multi-Conference on Artificial Intelligence Technology (MCAIT 2021) [74]
Artificial Intelligence in the 4th Industrial Revolution